

この記事ではJSON等の様々なデータフォーマットをRustの構造体に対応させるためのシリアライズ・デシリアライズフレームワークであるserdeについての解説します。ほとんどのユーザーは自分が定義したRustの構造体を様々なフォーマットに対応させるためにserdeを使う事が多いでしょうが、この文章では特に新たなフォーマットをserdeに追加する為の情報をまとめていきます。
Serialize, Deserializeとは
上述したようにserdeはJSONのような特定のフォーマットへの変換を行うためのライブラリではなく、そのようなライブラリを開発するためのフレームワークです。
Data Format
シリアライズというのは日本語では直列化と呼ばれることもありますが、データを一列に並べる事を意味し、デシリアライズというのはその逆の操作を指します。データを並べる目的はたくさんあります。データをディスクに書き出す、ネットワークを通して別のマシンに送る、あるいはそもそもメモリ上にデータを置いている状態でもデータは一列に並んでいます。ディスクに書き込む際はなるべく少ない容量で済むように圧縮して保存したり、ネットワークで送る際はシリアライズ・デシリアライズのコストを減らすような方式を採用したりと目的に応じて様々なシリアライズ形式を併用します。逆にデシリアライズはプログラムが外部から入力を得るために使われます。このようなシリアライズ形式の事をserdeではdata formatと読んでおり、この文章でもそのまま使います。
データフォーマットはシリアライズされたデータが本人以外にも読めるように正確に定義されている必要があります。現在までに様々な特性を持った多くのデータフォーマットが発明され、今ではほとんどの場合においてそれらのうちから用途に応じて適切なものを選べば良くなっています。例えば汎用で人間が中身を確認しやすいASCIIによるデータ記述形式としてはJSONが、プログラムの設定を記述する方式としてYAMLやTOMLが、ネットワーク上でデータをやりとりする際にシリアライズ・デシリアライズコストを抑えたい方式としてProtocol BuffersやMessagePackなどがあります。あるいは「C言語で構造体を定義した際にそれがメモリ上でどのように配置されるのか」自体が一種のデータフォーマットになっています。これらは仕様が定まっているため多くの言語でこれらを効率的に読み書きする為のライブラリが存在します。逆にCSVの様に非常に曖昧な仕様を使った結果、実装によって正しく読める場合と読めない場合があるものも存在します。
Schema
汎用なデータフォーマットではそのフォーマット自体で表現可能なデータが決まります。例えばJSONではプリミティブな文字列"str"や整数1、浮動小数点数3.1415の他にそれらの合成たるリスト[1, 2, 3]やオブジェクト{ "a": [1, 2, 3], "b": 4 }をどのようにシリアライズするかを定めています。
しかしアプリケーションの入出力としてJSONを用いる場合、入力のデータには例えばinput_directoryというディレクトリを表す文字列、nprocという並列数を記述する整数などといった特定のデータだけが必要になります。JSONで表現し得る全てのデータの集合からすると、非常に小さいデータの集合だけをアプリケーションは受け入れたいわけです。アプリケーション側で一旦JSONを読み込んだ後にアプリケーションが望んだデータであるかを判定する事も多いですが、ほとんどのアプリケーションでこの作業は必要となるのでアプリケーションに依らずにこの制約を記述する方法が開発され、スキーマと呼ばれます。
代表的なものとしてJSON Schemaや、あるいは初めからデータフォーマットにスキーマが付随しているProtocol Buffersのようなケースもあります。このようなスキーマはあるスキーマで定義された制約を他のスキーマでも使えるようにインポートする機能が備わっている事が多いです。データフォーマットだけでなく、プロセス間で通信を行って機能を呼び出すRPC(Remote Procedure Call)を記述するためにスキーマが使われることが多く、例えばgRPCはProtocol Buffersの機能を拡張して実装されていたり、OpenAPIの様に独自にREST APIを記述するものも開発されています。
スキーマの処理系にはその内容に応じた各言語の実装を生成する機能が備わっています。例えばProtocol Buffersのコンパイラprotocはスキーマで指定された型を定義し、バイナリデータからその型を構築したり逆に型をバイナリデータに出力するコードを自動生成します。あるいはエディタにスキーマを読み込んで設定ファイルを書く補助を行うような機能も多く開発されています。
Deserialize
様々なフォーマットからRustの構造体に変換する過程はデシリアライズと呼ばれます。この際にフォーマットからどのようにデータを取り出すのかについての性質を記述するのがDeserializer traitとその補助trait達です。
型の変換
例えば文字列として"1"が与えられたとき、これは&str型になりますが、数値は例えばusize型であるはずです。この様な変換を行う関数は整数として上手く認識出来るか、あるいは出来ないかの二通りが実行時に発生するので直和型であるResultを考える必要があります。
fn str_to_usize(input: &str) -> Result<usize, DeserializeError> { ... }
この様に静的に型が付いてない入力を型が付いた出力に変換する処理をDeserialize時に行う必要があります。実際にはRustの標準ライブラリにはFromStr traitが用意されており多くの型でこれが実装されています:
pub trait FromStr {
type Err;
fn from_str(s: &str) -> Result<Self, Self::Err>;
}あるいはTryFrom traitも同じような目的で存在します。
Parse
上で説明した様に、データフォーマットが許容する入力とアプリケーションが必要とする入力には差があります。特にスキーマが存在している時にはユーザーは入力をスキーマで指定された型に変換してほしいはずです。すると入力を処理の中にデータフォーマットだけで定まる部分とスキーマで指定された型に依存する部分が入ります。
例えば入力データフォーマットとしてJSONを用いてinput_directoryとnprocが欲しいとしましょう。例えば入力文字列は次の様になります
{ "input_directory": "./example/input.txt", "nproc": 2 }まず最初にやらないといけないことはこの入力文字列をJSONのオブジェクトとして見る事です。つまり空白を無視して{からオブジェクトが始まっている事を認識し、二つのキーバリューの組がある事を認識し、}でオブジェクトが終わることを認識します。この部分はJSONの仕様だけ実装出きることに注意します。つまり次のparseのような関数を実装できます。
enum JsonAny {
Integer(i64),
String(String),
Object(HashMap<JsonAny, JsonAny>),
}
fn parse(input: &str) -> Result<JsonAny, NonJsonInputError> {
todo!()
}
let input = parse(r#"{ "input_directory": "./example/input.txt", "nproc": 2 }"#).unwrap();
assert_eq!(input, JsonAny::Object(hashmap! {
JsonAny::String("input_directory") => JsonAny::String("./example/input.txt"),
JsonAny::String("nproc") => JsonAny::Integer(2),
});
例えば}が無かったりすればエラーを返す事にします。このJsonAny型はJSONとして取りうる全てのデータを表せる型です(実際にはJSONはもっと色々持てますがここでの説明に必要なパターンだけにしてあります)。この操作をここではParseと呼ぶことにします。するとDeserializeの過程は入力をParseする操作と、更にパース結果を目的のRustの構造体にマップする操作(Mappingと呼ぶ)からなります。この分類で言えば、serdeはParseの為のフレームワークではなく、Mappingの為のフレームワークです。実際にはParseを完全に行ってからMappingを行うのは計算時間・メモリ共に効率が良くないので両者を同時に行い、JsonAnyのような中間データを作らずに行う事が多くserdeもそう出きるような設計になっていますが、分かりやすい様にこの記事では順番に行う想定で議論します。
Deserialize trait
前置きが長くなりましたようやくserde::Deserializeとserde::Deserializerの話が始められます。名前が似ているこの二つのTraitはそれぞれ「何にDeserializeするか」と「何をDeserializeするか」を抽象化します:
| Trait | 抽象化する役割 | 実装する対象 |
| Deserialize | 何にDeserializeするか | ユーザーの構造体 |
| Deserializer | 何にDeserializeするか | データフォーマットを解釈する構造体(主にライブラリが提供する) |
Deserialize traitの役割はスキーマに似ています。serdeではDeserialize traitの実装を自動的に生成できる手続きマクロ #[derive(Deserialize)]が用意されているので次のように書くだけで実装が生成されます:
#[derive(Deserialize)]
struct InputData {
input_directory: String,
nproc: usize,
}Rustの構造体定義がスキーマ言語、手続きマクロがスキーマのコンパイラに対応します。ここではどんなデータフォーマットからこの二つのデータを取得するのかは決めていない事に注意します。serdeの強力な特徴として、この定義だけで複数のフォーマットから、例えばJSONからもTOMLからも同じようにこの構造体を構築できるという点があります。ここで自動生成されるDeserialize実装は、なにかしらのデータフォーマットからStringとusizeの二つのデータを取ってきて目的の構造体を構築するというものになります。つまりデータフォーマットから特定の型のデータを取り出すプロトコルが必要となり、それがserde data modelと呼ばれるものです。一方JSONのような特定のデータフォーマットをこのプロトコルとして使えるようにするためのTraitがDeserializerです。
#[derive(Deserialize)]が生成するコードについて見てみましょう。Rustでは#[derive(Debug)]のような言語が提供する自動でTraitを実装する機能がありますが、これをライブラリレベルで拡張出きるようにしたものがCustom deriveと呼ばれる手続きマクロの一種で、#[derive(Deserialize)]はserde-derive crateで提供されるCustom deriveです。手続きマクロはmacro_rules!で定義される宣言マクロと異なりRustのコード片を受け取りRustのコードを出力するように記述され、cargoによるコンパイル時に自動的にビルドされて実行されその出力したRustコードで置き換えられます。フル機能のRustが使えるため非常に自由度が高い一方、乱用するとどのようなRustコードが出力されているのか分かりづらくなってしまいます。この出力を確認するツールとしてcargo-expandがあります。これはcargo buildと同じように実行すると手続きマクロの出力結果を挿入した所でコンパイルを止めて結果のRustコードを標準出力に出してくれます。これを使って#[derive(Deserialize)]の結果を見てみましょう。これは大きく分けて
impl Deserialize for InputData- Visitor構造体の定義
impl Visitor for Visitor
の3つのパートがあります。但し余分な定義が外から見えないように少し工夫されています。このVisitor構造体というものが必要になる理由はDeserializeとDeserializerの定義を見てみると分かります:
pub trait Deserialize<'de>: Sized {
fn deserialize(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>;
} pub trait Deserializer<'de>: Sized {
type Error: Error;
fn deserialize_any(self, visitor: V) -> Result<V::Value, Self::Error>
where
V: Visitor<'de>;
// more deserialize_xxx
} Deserializer Traitの解説は後で行いますが、ここではそれぞれDeserialize::deserializeとDeserializer::deserialize_anyに着目してください。ユーザーはDeserialize::deserializeにデータフォーマット毎に作られたライブラリからもらったDeserializerを実装した構造体を渡すことでユーザーが定義した構造体を得ます。しかしライブラリを実装する方はその型を知らないまま実装しないといけません。そこでDeserializer::deserialize_anyは型引数としてユーザー型に対応した型Vを受け取ります。これをVisitor構造体とここでは読んでいます。つまりユーザーはDeserializeしたい型全てにVに相当する型を定義しなければなりませんが、これを#[derive(Deserialize)]が自動的にやってくれています。全体の手続きをまとめると次の図のようになります:
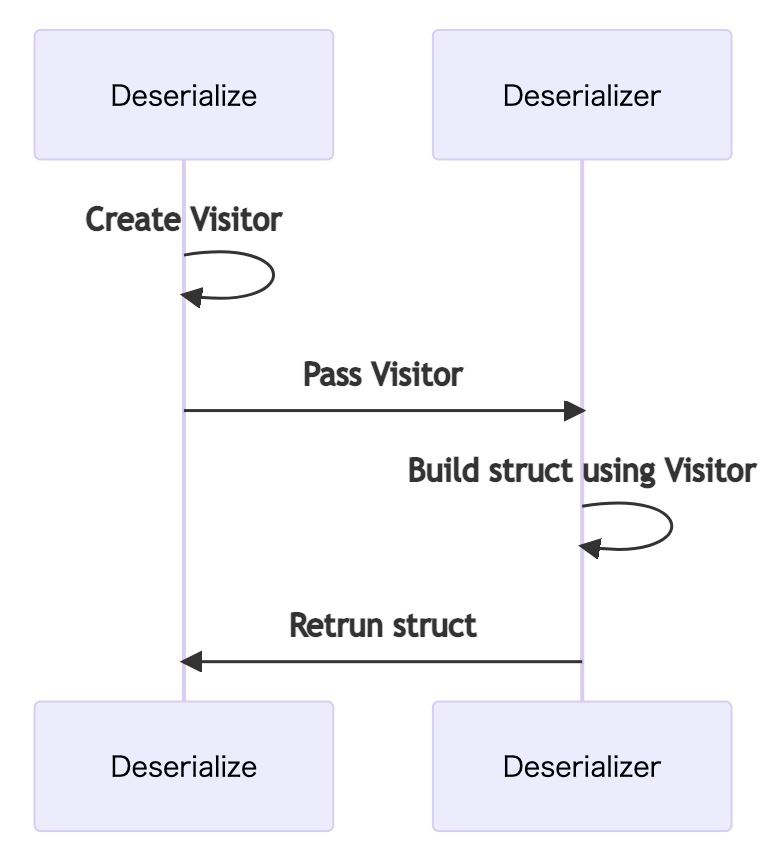
serde data model
serde data modelではDeserializeがDeserializerからデータを受け取れる際の型を導入します。ここではDeserializerのAPIに基づいてこれらを以下の様に分類します。
- プリミティブ型
bool,i8,i16,i32,i64,i128,u8,u16,u32,u64,u128,f32,f64,char
に加えて次を単純な構造を表すグループと呼びましょう:
| serde data model | Rust example |
string |
String |
byte_array |
[u8] |
option |
Option<T> |
unit |
() |
newtype_struct |
struct Millimeters(u8) |
これらは後に解説するVisitor Traitが直接扱える型です。次に独自のTraitが追加で必要になるグループ:
| serde data model | Rust example | Trait |
seq |
Vec<T>, HashSet<T> |
SeqAccess |
map |
HashMap<Key, Value>, BTreeMap<Key, Value> |
MapAccess |
さらにRustのenumに相当する構造に対応するためのEnumAccess, VariantAccess Traitを使う必要があるグループ
| serde data model | Rust example |
unit_variant |
E::A and E::B in enum E { A, B } |
newtype_variant |
E::N in enum E { N(u8) } |
tupe_variant |
E::T in enum E { T(u8, u8) } |
struct_variant |
E::S in enum E { S { r: u8, g: u8, b: u8 } } |
最後にDeserializerが追加でアノテーションを加える必要がある複雑な構造を表すグループ:
| serde data model | Rust example |
unit_struct |
struct Unit or PhantomData<T> |
tuple |
(u8,), (String, u64, Vec<T>), [u64; 10] |
tuple_struct |
struct Rgb(u8, u8, u8) |
struct |
struct S { r: u8, g: u8, b: u8 } |
Deserializer trait
Deserializer traitの定義は次のようになっています:
pub trait Deserializer<'de>: Sized {
type Error: Error;
fn deserialize_any(self, visitor: V) -> Result<V::Value, Self::Error>
where
V: Visitor<'de>;
// and more deserialize_xxx
} Deserializer trait実装の責任は実行時のデータに応じて、受け取ったVisitorを実装した構造体の一つの関数を呼ぶ事です。例えば上のJsonAnyの場合は次の様にvisit_i64かvisit_strを整数か文字列かによって呼び分けます(オブジェクト値については次節で扱います):
impl<'de> Deserializer<'de> for JsonAny {
fn deserialize_any>(self, visitor: V) -> Result<V::Value, Self::Error> {
Ok(match self {
JsonAny::Integer(i) => visitor.visit_i64(i)?,
JsonAny::String(s) => visitor.visit_str(&s)?,
_ => unimplemented!(), // Objectの場合は後で
})
}
...
} この場合ではJsonAny自身だけでどのような値として使うべきか定まっているのでdeserialize_anyを使います。
SeqAccess, MapAccess trait
serde data modelのうちプリミティブ型を含む単純な型のグループは以上の説明で扱えます。しかしそれ以外の型を扱うには追加で機能が必要になります。visit_seqとvisit_mapの定義を見てみましょう:
pub trait Visitor<'de>: Sized {
...
fn visit_seq(self, seq: A) -> Result<Self::Value, A::Error>
where
A: SeqAccess<'de>;
fn visit_map(self, map: A) -> Result<Self::Value, A::Error>
where
A: MapAccess<'de>;
...
}これらを使うにはSeqAccess, MapAccessを実装した構造体がそれぞれ必要になり、これは通常データフォーマット側で用意します。イテレータから変換出来るserde::de::value::SeqDeserializer及びserde::de::value::MapDeserializerが提供されているのでこれを使うか、あるいは自分で実装します。
EnumAccess, VariantAccess trait
次にvisit_enumの定義を見てみましょう。
pub trait Visitor<'de>: Sized {
...
fn visit_enum(self, data: A) -> Result<Self::Value, A::Error>
where
A: EnumAccess<'de>;
...
}RustのenumではCのenumの機能に加えて代数的データ型が表現でき、それに応じてどのVariantを選ぶのかとどんな値を返すのかを一緒に指定する必要があります。例えばnewtype_variantの場合を考えてenum E { N(u8) }にデシリアライズしたい場合、E::Nを使うことを決めるのがEnumAccessの役割で、u8の値を決めるのがVariantAccessの役割です。これは自分で実装する必要があります。
参考にruststep::ast::Nameの実装を示します:
pub enum Name {
Entity(u64),
Value(u64),
ConstantEntity(String),
ConstantValue(String),
}まずEnumAccessの実装は文字列としてVariantの種別を返します。これはDeserialize実装側で使われます。詳しくはEnum representationを見てください。
impl<'de, 'name> de::EnumAccess<'de> for &'name Name {
type Error = crate::error::Error;
type Variant = Self;
fn variant_seed(self, seed: V) -> Result<(V::Value, Self::Variant)>
where
V: de::DeserializeSeed<'de>,
{
let key: de::value::StrDeserializer = match self {
Name::Entity(_) => "Entity",
Name::Value(_) => "Value",
Name::ConstantEntity(_) => "ConstantEntity",
Name::ConstantValue(_) => "ConstantValue",
}
.into_deserializer();
let key: V::Value = seed.deserialize(key)?;
Ok((key, self))
}
} 次に選択されたVariant毎に返す値を実装します。Name型はserde data modelにおけるnewtype_variantとして解釈して欲しいので、newtype_variant_seedだけ値を返して、他はエラーを返します:
impl<'de, 'name> de::VariantAccess<'de> for &'name Name {
type Error = crate::error::Error;
fn unit_variant(self) -> Result<()> {
let unexp = de::Unexpected::NewtypeVariant;
Err(de::Error::invalid_type(unexp, &"unit variant"))
}
fn newtype_variant_seed(self, seed: D) -> Result
where
D: de::DeserializeSeed<'de>,
{
match self {
Name::Entity(id) | Name::Value(id) => seed.deserialize(id.into_deserializer()),
Name::ConstantEntity(name) | Name::ConstantValue(name) => {
seed.deserialize(name.as_str().into_deserializer())
}
}
}
fn tuple_variant(self, _len: usize, _visitor: V) -> Result
where
V: de::Visitor<'de>,
{
let unexp = de::Unexpected::NewtypeVariant;
Err(de::Error::invalid_type(unexp, &"tuple variant"))
}
fn struct_variant(self, _fields: &'static [&'static str], _visitor: V) -> Result
where
V: de::Visitor<'de>,
{
let unexp = de::Unexpected::NewtypeVariant;
Err(de::Error::invalid_type(unexp, &"struct variant"))
}
}
Links
以下は日本語の記事です:
- RustのSerdeの簡単な紹介
- [Rust] Serdeのシリアライズ/デシリアライズを試してみる
- Rust の serde を読む(1): serde の基本
- Rust の serde を読む(2): serialize を読む
- serdeのかゆいところに手が届くserde_with
現メンテナによる追記
現在RICOSでは、以下に挙げる 2 つのRustプロジェクトを保有しています。
今回の技術情報のテーマであるserde::Deserializerは、ruststepにおいて、STEPデータをserdeデータモデルに変換するために用いられています。
現在truckでは、ruststepを用いてSTEPで定義された形状をブラウザに表示するプロジェクトを進行中です。
もしご興味がありましたら、こちらもチェックしてみてください。



